Modern web development, SEO analytics, and data scraping are undergoing an unprecedented arms race. On one side are automation engineers who need to gather structured information, test user interfaces, and automate routine business processes.
On the other side are intelligent anti-bot systems like Cloudflare, Akamai, DataDome, and constantly evolving CAPTCHAs (reCAPTCHA, Cloudflare Turnstile, Arkose Labs).
Microsoft's Playwright framework has become the de facto industry standard for browser automation, having almost completely supplanted Selenium and Puppeteer. Its popularity is driven by cross-browser compatibility, out-of-the-box support for WebKit and Firefox, a powerful auto-waiting system for elements, and deep integration with the Chrome DevTools Protocol.
However, in its vanilla state, pure Playwright is absolutely defenseless against modern CAPTCHAs and anti-fraud systems. To successfully bypass protective mechanisms, engineers must build highly complex architectures that include fine-tuned browser fingerprint spoofing, management of residential proxy pools, and, as the most critical link, the integration of reliable CAPTCHA recognition services.
The Anatomy of Paranoia: How Modern Web Application Firewalls See Your Browser

Before moving on to the integration of third-party APIs to solve these puzzles, it is essential to fundamentally understand why a CAPTCHA appears on the target page in the first place. In today's reality, a CAPTCHA is rarely a static element hardcoded into a form's HTML. Most often, it is a dynamic response from an intelligent Web Application Firewall (WAF) to a suspicious visitor profile or an anomalous network pattern. Anti-bot systems analyze hundreds of parameters and render a verdict even before the DOM tree is fully rendered by the browser engine.
Practice and deep reverse engineering show that the detection of tools like Playwright occurs on several independent yet interconnected levels.
First, there are basic headless mode leaks. By default, browsers launched without a graphical user interface possess specific, easily detectable markers. Furthermore, such environments typically lack plugins, language settings often do not match the locale of the IP address, and the User-Agent header contains the telltale substring HeadlessChrome.

Second, hardware fingerprints (also known as Browser Fingerprinting) come into play. Advanced security systems like Cloudflare use hidden canvas elements to render off-screen graphics, subsequently hashing the result.
Because headless modes especially when run in Docker containers on Linux servers lack many proprietary system fonts and rely on software graphics renderers (e.g., SwiftShader instead of full GPU acceleration), the resulting hash is instantly identified as a server environment, leading to an immediate block. Similarly, WebGL and Audio Context fingerprints are analyzed, creating a unique hardware snapshot that cannot be altered simply by deleting cookies.

Third, the analysis drops to the network level (TLS and HTTP/2 Fingerprinting). Cloudflare and similar protection providers deeply analyze TLS handshake parameters and the sequence of HTTP/2 protocol frames. If your browser claims to be the latest version of Google Chrome on Windows 11 at the JavaScript level, but sends cryptographic network packets characteristic of the standard Node.
js library or the Python requests module, your trust index plummets to zero. This creates a "mismatch" a discrepancy between the declared profile and the actual network behavior which is guaranteed to trigger a Cloudflare Turnstile challenge or a hard connection reset.
Finally, client-side behavioral analysis plays a critical role. Modern anti-bot scripts track mouse movements, scrolling speed, and keystroke intervals. The absence of natural, chaotic cursor micro-movements, instantaneous clicks on exact mathematical coordinates of elements, and overly consistent timeouts between actions devoid of human entropy will instantly expose an automation script.
The Illusion of Invisibility: Stealth Plugins and Anti-Detect Solutions
To minimize the risk of verification screens appearing, the first and mandatory step is always the implementation of browser masking. The baseline and most common solution in the Node.js ecosystem is the use of specialized wrapper libraries. Specifically, the combination of the playwright-extra package and the puppeteer-extra-plugin-stealth plugin has become the de facto industry standard for basic script anonymization. This plugin dynamically overrides critical properties of the navigator object, spoofs the WebGL vendor, adds mocks for missing plugins, and diligently hides obvious traces of automation, making a headless browser look like a standard user's Chrome.
However, the harsh reality is that a Stealth plugin alone is drastically insufficient for stable scraping. Protective mechanisms have advanced significantly. As experts note, Cloudflare looks much deeper than simple browser signals, and even with stealth mode enabled, a page will often hang endlessly on the "Checking if you are human" stage or return a blank white screen. Overriding properties via JavaScript injections has its limits, as advanced anti-bot scripts have learned to detect the very act of tampering with native browser object prototypes.
In cases where standard masking plugins fail, developers resort to full-fledged anti-detect browsers like MostLogin.
Nevertheless, even utilizing the most expensive anti-detect browser and elite residential proxies does not guarantee complete freedom from CAPTCHAs. At the slightest deviation in behavioral patterns, or when accessing highly secure resources (such as bank login pages or registration forms), the security system will inevitably trigger a visual or background check. It is at this critical juncture that specialized programmatic recognition API services enter the scene; without them, full automation is fundamentally impossible.
CAPTCHA Recognition Services Comparison: Clash of the Automation Titans
The anti-CAPTCHA service market has undergone a colossal transformation over the past few years. While at the dawn of web scraping the industry relied exclusively on massive manual recognition farms where operators in developing countries typed out distorted text from images today, the technology is divided into classic crowdsourcing networks and highly advanced, AI-driven hybrid solutions. In this article, we will focus on two key players that are diametrically opposed in architecture but equally effective: 2Captcha and SolveCaptcha.
2Captcha: Absolute Universality Through Crowdsourcing
2Captcha is an industry veteran. Its architecture fundamentally differs from trendy neural network startups: it is built on a global, decentralized network of real human workers. The system routes incoming API tasks in real-time to thousands of operators worldwide, who solve visual and logical puzzles manually in exchange for micro-rewards.
The primary and undeniable advantage of this approach is total universality. Thanks to human intelligence, 2Captcha can solve absolutely any CAPTCHA, regardless of how convoluted it is. The service effortlessly handles legacy text CAPTCHAs, all variations of Google reCAPTCHA (v2, v3, Enterprise), highly complex multi-step graphical puzzles from Arkose Labs (FunCaptcha), proprietary local protections (e.g., Yandex or VK CAPTCHAs), and fundamentally new algorithms that generative AI models have not yet had time to master.
2Captcha's performance is characterized by supreme stability and predictable business outcomes. The probability of a CAPTCHA being solved correctly approaches 99%. Incorrect answers account for no more than 1-5% of the total request volume, and an automated refund mechanism via the API (reportbad function) is provided for them. Furthermore, the service boasts an incredibly broad ecosystem: practically any modern scraping tool, SEO software, or browser extension features out-of-the-box integration with 2Captcha.
However, relying on human labor introduces specific vulnerabilities. The main trade-off is recognition speed. Solving a complex graphical task, such as reCAPTCHA v2 or a complex Cloudflare Challenge, can take anywhere from 15 to 60 seconds during peak system load or when there is a shortage of available operators. In time-sensitive tasks such as high-frequency order book monitoring, NFT sniping, or booking interception, where every millisecond counts such delays can render a script ineffective.
SolveCaptcha: Hybrid Architecture and Neural Network Speeds

On the opposite end of the technological spectrum lies SolveCaptcha a relatively new player in the market that has made a loud entrance by implementing a hybrid recognition architecture. The platform positions itself as an AI-first solution, striving to combine the lightning speed of machine learning with the reliability of human recognition (human-fallback).
SolveCaptcha's internal routing operates intelligently: as soon as a task hits the server, it is instantly analyzed by proprietary ML models. Simple text CAPTCHAs, distorted images, and popular invisible tokens (such as reCAPTCHA v3 or the basic version of Cloudflare Turnstile) are processed by neural network clusters in just 3-5 seconds. If the algorithm encounters a critical drop in its confidence score for example, when a new, previously unseen FunCaptcha pattern or a complex logic puzzle appears the request is seamlessly routed to a pool of live operators without any client intervention.
Utilizing machine learning on the front line allows SolveCaptcha to significantly reduce processing costs. As a result, the platform's pricing is often among the most attractive on the market for standardized tokens. Recognizing 1,000 reCAPTCHA v2 puzzles will cost a webmaster a flat rate of $0.55 USD, while complex Cloudflare Turnstile or reCAPTCHA v3 tokens cost only $0.80. At the same time, the "Pay for Success" policy remains intact you are billed exclusively for successfully solved tasks.
A strategic advantage of SolveCaptcha is its complete API compatibility with the market leader. The service developers have implemented an HTTP API that 100% replicates 2Captcha's protocols (utilizing the in.php and res.php endpoints). This means that migrating massive, legacy scraper codebases to SolveCaptcha is completely painless and requires an SEO specialist to only change the base domain in the configuration and update the authorization key.
The platform also provides granular financial control tools. Webmasters can set strict maximum cost-per-thousand (CPM) limits via the API. If the algorithms fail and the current load on the human server exceeds the established budget ceiling, the API returns an ERROR_NO_SLOT_AVAILABLE status, protecting the user's balance from unexpected deductions during peak hours.
Analytical Comparison of Architectures and Metrics
The Fundamental Protocol for Recognition API Interaction
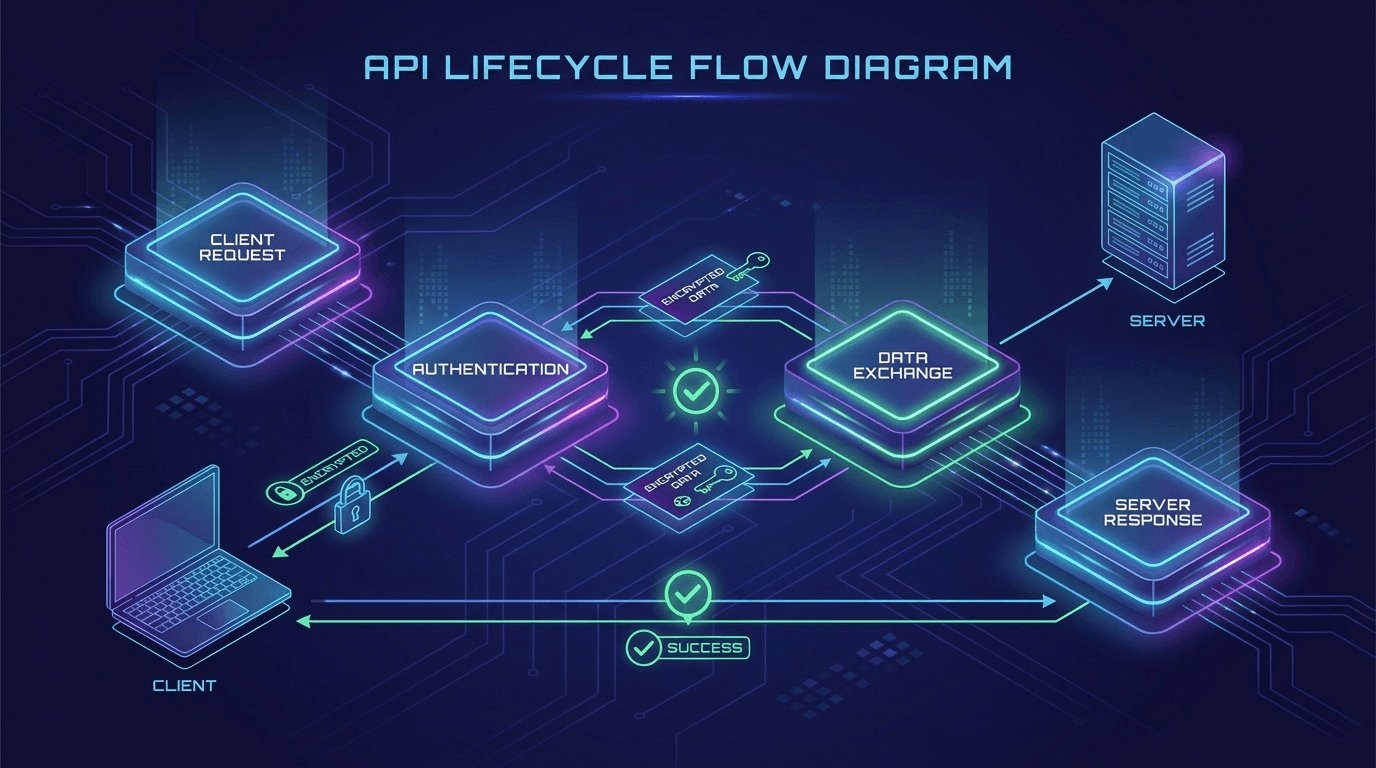
Regardless of the chosen provider, both services utilize an identical asynchronous interaction architecture based on the HTTP protocol. A deep understanding of this lifecycle is critical for implementing a robust wrapper around Playwright instances. The process always consists of four sequential phases:
- Submit Phase: When your automated script reaches a protected page, it must locate the CAPTCHA container, programmatically extract the necessary parameters (usually the public sitekey and the url of the current page), and make a POST request to the in.php endpoint. The server immediately returns a unique task identifier, typically called a Task ID or Request ID.
- Timeout Phase (Initial Wait): After receiving the identifier, the script must pause execution. Continuously spamming the API servers is pointless and leads to temporary blocks on the developer's IP address. Documentation strictly recommends waiting 20 seconds for complex tokens like reCAPTCHA Enterprise, and 5 seconds for AI-oriented tasks before making the first status request.
- Poll Phase (Long Polling): The script enters a Long Polling loop, periodically sending GET requests to the res.php endpoint, passing the previously obtained Task ID. The interval between requests is usually 3 to 5 seconds. While the service is processing the task, the API returns the string response CAPCHA_NOT_READY.
- Retrieve & Inject Phase: Once the status on the server changes to successful, the API returns the completed token (usually in the format OK|TOKEN_STRING). Having obtained this cryptographic key, Playwright must carefully inject it into the page's DOM tree typically into a hidden textarea field - and then simulate a natural click on the form submit button or programmatically invoke a callback function implemented by the site developers.
The complexity of the parameters passed during the Submit phase directly depends on the CAPTCHA type. While a simple Base64 image string is sufficient for basic graphics, the requirements for modern behavioral barriers like Cloudflare Turnstile or Arkose Labs FunCaptcha are much stricter. Often, you must pass not only the sitekey, but also the full pageurl, the exact userAgent your Playwright instance is running, and sometimes specific parameters like surl or encrypted blob data generated by the security scripts in real-time.
Industrial Automation Infrastructure: Proxy Management and Session State Preservation
The architecture of a reliable parser is not limited to injection code alone. It is conceptually vital to understand that any CAPTCHA recognition API is exclusively a mechanism for obtaining cryptographic tokens (the answers to the puzzle). No matter how clean or trusted the token received from 2Captcha or SolveCaptcha is, using it will not save your script from an immediate ban if that token is submitted to the target server from a blocked or suspicious IP address. Utilizing cheap IPv4 addresses from datacenter pools is the most common rookie mistake. Systems like Cloudflare Enterprise simply will not bother validating the token, having preemptively flagged the entire subnet as malicious.
Deep Proxying (Residential & Mobile Proxies): For successful operations with Playwright, it is absolutely critical to use high-quality rotating residential or mobile proxy networks. These IP addresses belong to real ISPs and physical devices, making them indistinguishable from regular user traffic. The proxy server is attached to Playwright at the very earliest stage - during the initialization of the browser context.
There is a crucial architectural nuance here: when using recognition services, it is highly recommended to forward your working proxy server directly into the API service. Both of the providers discussed (2Captcha and SolveCaptcha) support this feature by passing the proxy parameter in the POST request. Why is this necessary? It ensures that the operator or AI algorithm solving your CAPTCHA is doing so from the exact same IP address that your Playwright script will use a second later to submit the finalized token. A discrepancy between the IP address that requested the visual CAPTCHA and the IP address solving it (the so-called Mismatch IP Protocol) will, in the vast majority of cases, lead to the immediate invalidation of the token in strict Cloudflare or Arkose Labs security configurations.
Synthesis of Technologies: Conclusions and Strategic Recommendations for Tooling Selection
The global confrontation between automation system engineers and WAF developers long ago evolved past the stage of simply writing scripts into a full-scale war of budgets, architectural patterns, and computational power. As this deep dive clearly demonstrates, finding the answer to the seemingly simple query how to bypass captcha in playwright cannot be reduced to mindlessly installing a single npm package. It is a complex, multi-level architectural approach that organically incorporates core-level browser fingerprint spoofing, management of clean residential proxy pools, competent session state caching, and, as the ultimate weapon, the application of commercial APIs to bypass cryptographic and visual barriers.
Regarding the choice of a specific CAPTCHA recognition vendor, the recommendation strictly depends on the project's underlying business logic and the specifics of the target resources:
- First, if the absolute priority of your architecture is supreme fault tolerance and the ability for scripts to handle rare or proprietary local protections (e.g., when scraping government sector websites, regional classifieds in CIS countries, or services with specific text checks) - the strategic choice is obvious and leans in favor of 2Captcha. The presence of a massive, geo-distributed staff of live operators guarantees the resolution of even those visual paradoxes that are guaranteed to break any existing neural network algorithms. Official support for stable SDKs, particularly the highly refined 2captcha-python package, makes the deployment of this solution into a production environment as reliable and predictable as possible in the long term.
- Second, if your scraper's architecture demands extreme data processing speed, support for massive parallelism (hundreds of simultaneously open Playwright contexts), and strict operational cost optimization - the technological leader is the hybrid SolveCaptcha service. Using advanced ML engines for the instantaneous rendering of standardized reCAPTCHA tokens and Turnstile validation in 3-5 seconds provides an insurmountable competitive advantage in time-sensitive scraping. This is critically important when working with cryptocurrency exchanges, e-commerce aggregators, or ticket booking systems, where every lost second translates into lost revenue. Furthermore, the absolute protocol compatibility of their API with classic industry standards allows DevOps engineers to transition their entire production environment to new high-speed rails by modifying just a couple of configuration lines of code.
Integrating such high-level solutions into a Playwright environment is the art of creating an intelligent system capable of flawlessly emulating live user behavior across all technical layers: from correct network packet sorting and generating plausible WebGL fingerprints to solving highly complex behavioral puzzles with a final Score of 0.9. Only a systematic, careful approach to browser context configuration, the use of tested official integration packages (such as solvecaptcha-javascript and twocaptcha), and filigree control over network states will ensure your scripts run uninterrupted, even under the most aggressive restrictions of today's paranoid web standards.